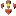Функция распределения содержит наиболее полную информацию о случайной величине. При выборочных исследованиях ее аналогом является эмпирическая функция распределения. В R ее можно построить следующим образом. Пусть х — вектор анализируемых данных:
> x1 = sort(x) > v = seq(from = 1/n, to = 1, by = 1/n) > plot(x1, v)
На рисунке приведен пример построения эмпирических функций распределения для SJR индекса публикационной активности...
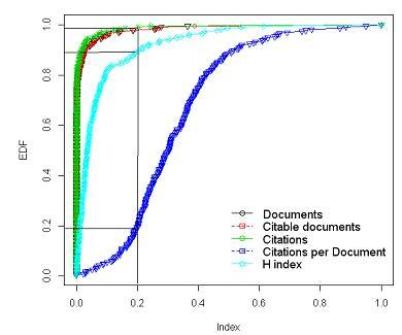

Функция coplot(), входящая в базовую «комплектацию» R, предназначена для построения т.н. " conditioning plots ". Это название можно перевести на русский язык как " категоризованные графики ". Суть здесь сводится к тому, что анализируемые данные разбиваются на отдельные категории (например, в соответствии с уровнями какого-то фактора), для каждой из которых строится свой график (= панель ) определенного типа. Все эти графики затем...
По роду деятельности мне в последнее время приходилось часто иметь дело с анализом данных, полученных при помощи технологии микрочипов (см., например, здесь ). Эта технология позволяет одновременно измерить уровни экспресии тысяч генов и сравнить их в образцах из разных условий (например, у больных и здоровых людей, или в культурах клеток, обработанных и не обработанных каким-то лекарственным средством, и т.п.).
...
...
Приглашаю всех на свой сайт-блог о системе статистических вычислений R:
r-analytics.blogspot.com
Буду публиковать много примеров анализа и визуализации данных, а также новости о R.
r-analytics.blogspot.com
Буду публиковать много примеров анализа и визуализации данных, а также новости о R.
Как мы знаем, использование двухвыборочных критериев, способом показанным в статье « Сравнение двух выборок в R », для попарного сравнения более чем двух групп неправильно. Множественное сравнение необходимо проводит специальными тестами. Иначе нам не избежать ошибки первого рода, когда исследователь находит различия там, где их нет. Существует множество методов, являющихся вариациями теста Стьюдента, от которого они отличаются...
Выложил на своем сайте описания 100 книг по использованию R. Только библиография и краткое описание книги со ссылками на книгу в Google Books и amazon
Книги по языку R
Книги по языку R

Анонс обзора специализированных пакетов R для зоологического/экологического и более общего пространственного анализа, вывешен на сайте gis-lab.info, http://gis-lab.info/qa/rspatial.html
Ришат, здравствуйте! Рад был обнаружить такую группу, поскольку сам пользуюьс R, и часто не хватает возможности проконсультироваться.
Мне кажется, низкая активность в групе отчасти связана с ее названием - медицинскя направленность. По моему, реалистично собрать сообщество для обсуждений, только привлекая и экномистиов, и биологов, экологов, социологов.
Мне кажется, низкая активность в групе отчасти связана с ее названием - медицинскя направленность. По моему, реалистично собрать сообщество для обсуждений, только привлекая и экномистиов, и биологов, экологов, социологов.
Научно-практическая интернет-конференция "Наука и инновации в медицине - 2009"
 http://www.sqlab.ru/index.php?option=c..
http://www.sqlab.ru/index.php?option=c..
Приглашаем Вас принять участие в научно-практической Интернет-конференции «Наука и инновации в медицине - 2009», которая начнет работу 1 ноября 2009 года на сайте www.sqlab.ru.
В статье " Сравнение двух выборок в R " рассказано о реализации методов Стьюдента и Уэлша (Welch) на примере решения 1-4 задач 4 главы книги Медико-биологическая статистика. Показан способ написания несложной функции для сравнения групп по критерию Стьюдента при отсутствии первичных данных, т.е. на основе средних, стандартных отклонений и размере выборок. Так же показан способ импорта таблиц из внешних файлов формата *.csv и еще...